Repository
In the MoQu.bsxp BIMSens App, navigate to the section Configuration > Settings, use the Repositories panel to edit the Project and Repository names as required. We can create a new Repository too if needed.
Repository options are grouped in 4 sections:
- Files: all options regarding filtering and selection of files to open
- Metadata Extraction: options for extracting model meta data from folder path and file name during indexing
- History: options for managing model indexing and retention over time
- Settings: other misc stuff
Files Section
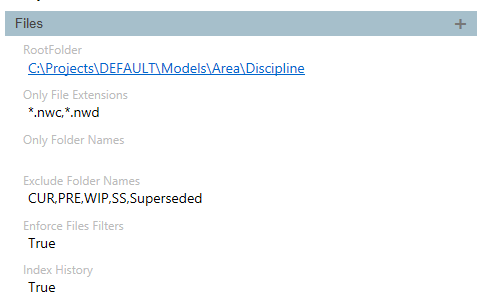
With the Repository selected, under Repository Settings, in the Files section:
- Click the Root Folder field and edit to a valid folder containing the models files to index. The files can be anywhere in the root folder specified, or in any of its sub folders recursively.
- Choose the File Extensions to accept, as a comma delimited list with wild card, e.g. *.nwc,*.nwd. Note: avoid using both the native format and the Navisworks cache format (e.g. rvt and nwc) as the nwc file will be generated automatically by Navisworks when opening the rvt, resulting in double indexing.
- Additional filters can be specified to exclude or include files that are or are not in specific folders.
- Finally under this section, turn the Index History setting on or off. When turned off, if multiple files resolve to the same name only at different version/date, MoQu will attempt to index only the latest one. Note that this setting has most impact when running the index for the first time on a directory with a lot of backlog file versions that can be ignored. When running MoQu regularly, for instance on a daily schedule, the files are indexed each time they are updated regardless. The user can still go into the Models tab and delete the history manually.
|
|
|
|
|
The Root Folder can be a sharepoint folder url, in which case MoQu will temporarily download the file locally if they need indexing. There are several requirements to be met for direct Sharepoint sync to work: 1. The user need to have login access at the site/sub-site root (not admin, just login, but not simply a shared folder link either) 2. If the folder is on a sub-site the root of the sub-site need to be marked in the Root Folder field with a doubled forward slash '//', e.g. https://company.sharepoint.com/sites/SITE/SubSite//Folder1/Folder2/... so that MoQu knows to attempt login at this level rather than the site root |

|
|
|
|
|
Sharepoint most often requires OAuth with MFA when logging in, which includes a mandatory pop-up form for the user to authenticate. As a result a scheduled task configured to run overnight will not work when targeting a Sharepoint repository as the pop-up form requires Windows to be started with a graphic interface. The work around is to create an app-only Sharepoint login (done by the Azure AD admin), grant this login permission on the target site (done by Sharepoint Site admin), and use that login instead in the scheduled task. |

Metadata Section
In the Patterns section, define the optional Model meta data extraction patterns.
Patterns are used by MoQu when reading models files from the disk to infer meta data of 3 types:
- Spatial, the 'Where', as Areas
- Functional, the 'What', as Discipline and
- Temporal, the 'When' as Stage, Revision, Version, Release
When a Pattern is specified, it is made of 3 directives, a required Path and an optional Split and Split Index, e.g. '2[-_]1'
1. Pattern Path
The Path defines the part of the file Full Name to read, as a position relative to the Root Folder:
- '0' is the Root Folder,
- positive numbers are descendant folders,
- negative numbers are ancestor folders.
There are in addition 2 shortcuts,
- 'f' to target the file name and
- 'l' for the last folder level
- 'l' can be composed with a negative number to climb back the folder tree, e.g. 'l-2' is the 3rd folder before last
The path specified for the Repository Root Folder hence directly impacts the Pattern Path directive, for instance with the path provided above:

If this Root Folder is changed to a higher level:

2. Pattern Split
The optional Split directive defines where to split the value obtained from the Path directive. the Split directive is made of a pair of square brackets, surrounding the list of character(s) used to split the value, e.g. the Split '[.,-]' splits a value by dot, comma and hyphen, hence the value 'dd.MM.yyyy-AFC' would be split in 4 parts.
3. Pattern Split Index
When the Split directive is used, a Split Index to select the part of the Split result at the given index. the Split Index support the 'l' shortcut and its negative climb option like the Path directive. In the example above where the Split returned the list {dd,MM,yyyy,AFC}, each part can be accessed from its index from 1 to 4.
The Pattern can be composed of multiple Sub Patterns to constitute a hierarchy, for instance of Discipline and Package. Pattern composition is achieved by combining Patterns separated by a backslash '\', e.g. Discipline\Package -> 2P\3.
Consider the following example:
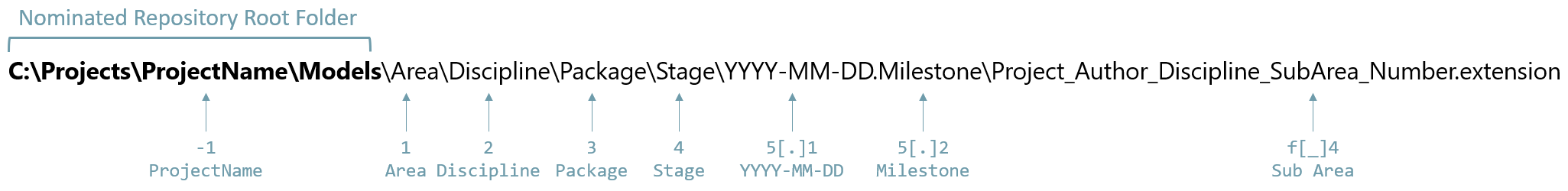
A possible configuration of the MoQu Pattern section would be:
- Area Pattern: -1\1\f[_]4 -> ProjectName\Area\SubArea
- Discipline Pattern: 2\3 -> Discipline\Package
- Release: 5[.]1 -> YYYY-MM-DD
- Milestone: 5[.]2 -> Milestone
|
|
|
|
|
|

History Section
In the History section, define the condition to index a file based on its history, or 'Temporal Status'
- Index History: set whether to index or not files that are older than already index files (models with the same key)
- Models Expiry: set the time in days after which a model is considered Expired
|
|
|
|
|
The Index History flag is useful when indexing large repositories retrospectively, and catching up with many versions of many models. It is for this very common scenario that the Models Expiry and associated After Expiry policies are in place, so that models that have change status can be cleaned up and the database can stay leaner. |
- After Expiry: select the action to perform on expired models, one of:
- Delete: the model, its components and attributes, as well as cached process results such as Schema Check and Schedule are deleted entirely.
- Archive: the components and attributes are deleted, but the process summary results and model information are kept
- Keep: everything is retained
- Always Retain: allows you to select an option to flag some models as not being subject to Expiry policies:
- Earliest: always keep the model that is the earliest/baseline for a Model Key
- Previous: always keep the model that is the one just before the latest/last for a Model Key
- Milestones: always retain models that are flagged as Milestone for a Model Key, with 2 sub modes:
- All: all versions of a milestone are kept
- Final: only the latest version of each milestone is kept (i.e. if an AFC model is updated and indexed 3 times for instance R00, R01 and R02, only R02 is kept)
|
|
|
|
|
MoQu uses Stages, Revision, Version and Release meta data, along with Versioning rules, and Modified date to sort models historically. The sorting can be audited from the Models page in the models table, under Versioning, where the assigned Temporal Class is shown, along with the Archiving pending action based on After Expiry policies. |
Settings Section
The last section of the Repository configuration contains miscellaneous settings:
- Allow Models With No Component: Index Model even if the Selection Rules resolve to no selection. This is useful to index reference models such as Lidar, terrain and interface projects
- Ignore Wireframe: Ignore components picked up by the Selection Rules, that are made exclusively of wireframe
- Inherit Attributes: Whether or not components inherit attributes from parent nodes in the 3D scene tree. Note that inherited attributes cannot override local attributes
- Parse Units: Whether or not to attempt parsing of units in string values, such as '25 mm'; see Units Parsing for more info
- Ignore Values: Values to treat as null or missing and not to index so as not to bloat the database
With the Repository configured we could now start using the application for various use cases such as Model Analysis.
Alternatively in order to understand all settings we can move across to the last 2 panels: Indexing Rules (or Selection Rules) and Attributes Rules.
Next
Indexing Rules | Basic Use Case | Advanced Processes